Human-Inspired Agent Design in Web Automation: From Principles to Practice
Justin Takamine
Co-Founder & CTO
Mar 18, 2025

Summary
We introduce a groundbreaking multi-agent system for web automation that suggests that agent cardinality (the number of agents working in concert) could represent a new scaling dimension in AI, opening exciting directions for future research and applications. Our approach is directly inspired by the coordination and specialization strategies used by effective human teams. By translating human organizational principles into novel computational techniques, our system achieves state-of-the-art performance on the Mind2Web benchmark, significantly outperforming leading systems such as OpenAI’s Operator and Anthropic’s Computer Use.

Invisible (93%) outperforms OpenAI (71%) and Anthropic (45%) on Mind2Web benchmarking.
Human-Inspired Agent Design
Large language models (LLMs) and large reasoning models (LRMs) have shown excellent performance on a variety of benchmarks. However, individual models still can’t handle many valuable tasks reliably and efficiently. Single model LLM-based agent solutions struggle to solve many multi-hop tasks, with errors ranging from failing to identify the correct “next step” to inaccurate translation of the next step into the agent’s action space.
A natural question is whether multiple models, working in concert, could solve these problems. A challenge in that case would be the orchestration of these models. For inspiration on effective orchestration, we look to the principles and patterns of a time-tested analog: effective human teams. We examine how teams of humans can reliably accomplish goals that a single human cannot, and adapt these collaborative concepts to a system of multiple AI agents. In particular, we focus on two concepts: coordination and specialization.
Coordination
Coordination is how a team focuses effort towards a shared goal. A well-coordinated team breaks down complex problems and delegates each sub-problem to the right team member. Each team member focuses on understanding their specific goal and its relevant context—allowing them to plan and act reliably and efficiently. The team leader ensures their team has the right skills to tackle the goal, and will modify the team if not (e.g., hiring an expert). The leader also monitors team members’ progress to ensure each workstream is moving efficiently toward the overall goal.
As an example, an engineering team may effectively coordinate by setting clear OKRs, holding daily standups, performing thorough code reviews, and hiring strategically. These processes collectively ensure the team continually assesses progress, quickly adapts to challenges, and steadily advances toward achieving the overall goal of delivering a good product.
Importantly, coordination is hierarchical; i.e., it happens across multiple levels of teams. Large organizations delegate high-level goals to medium-size teams who delegate projects to small teams who delegate tasks to each team member. At each level, the same processes of problem breakdown, work delegation, and output checking ensure the whole system converges as one towards a common goal.
Specialization
In practice, almost every human organization features specialization. For example, an engineering team may have one team member specializing in low-level storage, another in networking, and another in developer tooling. Highly robust support for specialization is typically necessary for organizations to be effective.
To solve deep sub-problems, some members of the organization must develop deep expertise in just a few areas. Specialists will develop knowledge and strategies that are optimized for their sub-domain. At the same time, the organization in aggregate must maintain expertise coverage across the full problem domain, which requires the coordination of multiple specialists.
Crucially, specialization allows individuals to focus their efforts on just the specific elements of an overall goal where their expertise can make the greatest impact, thereby enhancing efficiency and deepening the overall quality of their solution.
Our human-inspired approach translates these principles of coordination and specialization from real-world teams into the design of multi-agent systems. In capable organizations, individual specialists function within a coordinated framework that promotes collective problem-solving. In the following section, we describe a novel set of web automation techniques adapted from this conceptual blueprint.
Human-Inspired Web Automation Agents
Web automation is a complex domain because of the unpredictability of website designs, API response times, and interaction patterns. Existing AI agent design patterns (such as LLM-as-a-judge or consensus voting), while helpful, are not yet sufficient. We advance the state-of-the-art in web automation with three novel techniques inspired by human teams and the principles of coordination and specialization: dynamic hierarchy, adaptive scene representation, and retrieval augmented imitation learning (RAIL).
Dynamic hierarchy
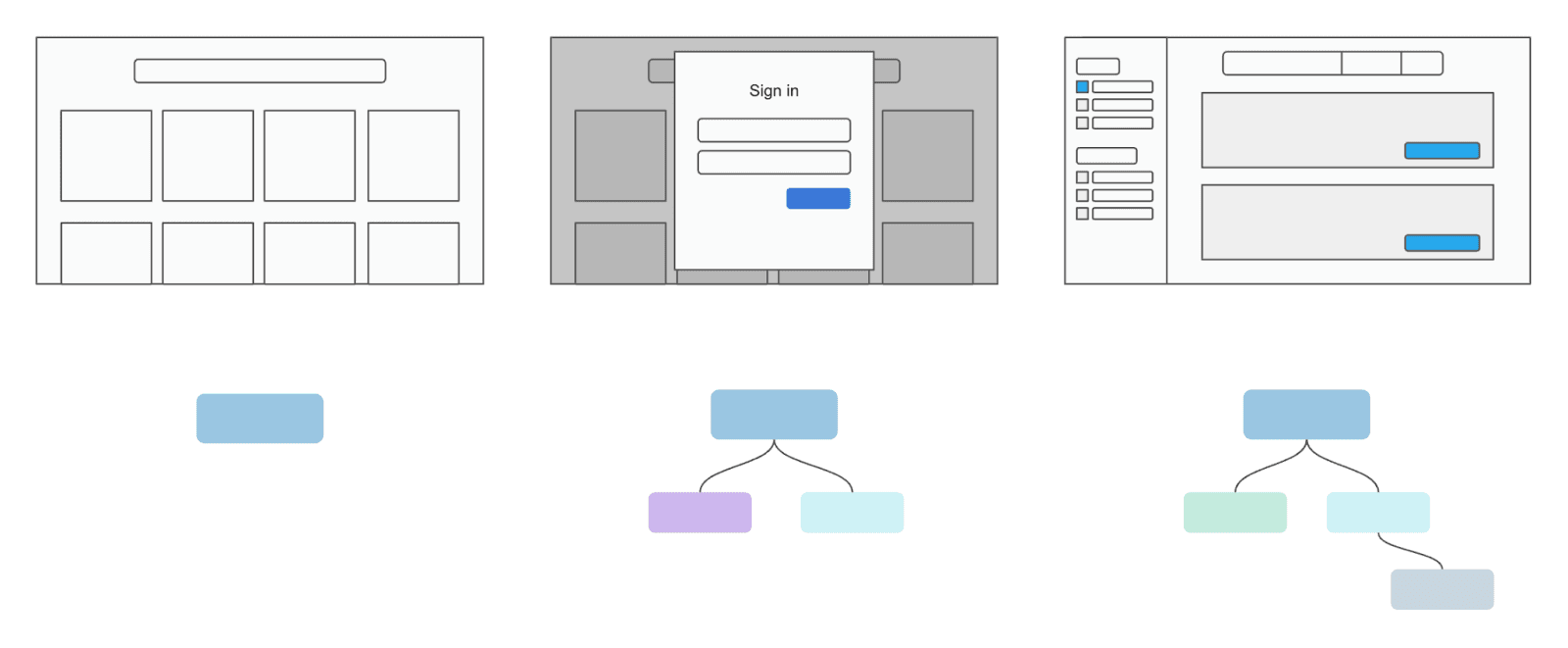
The best human teams adapt to the complexities of a task by delegating problems to specialized experts as they arise. With a large breadth of skills across the team members, the team doesn’t need to predict every problem. Instead, it can analyze, delegate, and solve each problem on the fly.
A similar strategy is required to solve complex problems in web automation. Almost every part of the web is dynamic: a given API may vary in response time from 100ms to 700ms, or a page might unexpectedly implement infinite scrolling instead of pagination controls. More generally, client-side script execution, incremental UI rendering, and state-dependent functionality cause problems for static workflows. A pre-defined agent execution plan can’t predict, and therefore can’t handle, all these variations.
Dynamic hierarchy is a technique in which each agent can delegate tasks to more specialized agents at runtime. This approach removes the need to predict variations or pre-define the execution patterns of the agents. Instead, like a well-coordinated human team, the multi-agent system can adapt to and tackle problems as they surface.
Dynamic hierarchy is especially suited for the web, where there are common patterns (e.g., logins, forms, feeds) that benefit from dynamic use of specialized agents. Some complex problems even benefit from multiple sub-hierarchies of specialized agents. For example, a generalist web navigation agent may encounter a login page and delegate that to a specialized login agent. The login agent executes the login function, then encounters a two-factor authentication (2FA) challenge, at which point it can then delegate that task to a specialized 2FA agent.
Adaptive scene representation
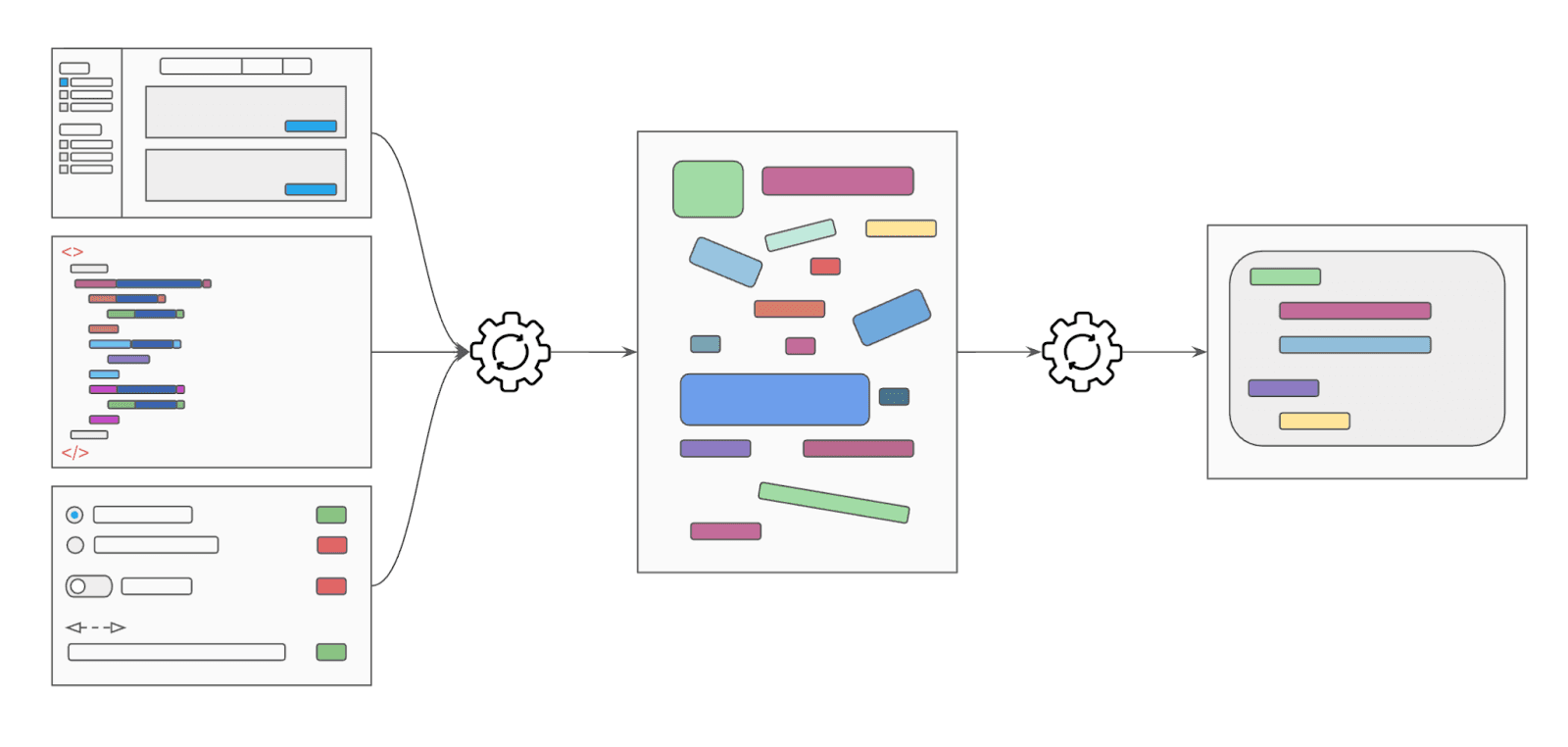
To make decisions, humans transform and filter vast amounts of raw sensory input to create a coherent, focused representation of the environment at hand. Humans also adapt this representation to their specific goal. For example, a project manager, with the goal of team cohesion and project velocity, will transform fragmented conversations with team members and disparate progress documentation into a concise representation of the project—a project dashboard showing the status, blockers, and timeline.
Web agents have access to two primary types of environmental data: visual data (e.g., screenshots) and HTML content. Both can be quite noisy, and each one on its own has a distinct set of weaknesses. With just screenshots of the webpage, an agent can see the visual elements on the screen but doesn’t know what’s beyond the viewport, and may struggle determining element semantics especially for poorly designed websites. With just the HTML, an agent may miss visual cues like rendered color for error states, or emphasis implications (e.g., a modal in the center of the screen is likely more important than something obscured behind the modal).
To address these challenges, we apply the human-inspired concept of adaptive scene representation to process all the sensory input available to a web agent (screenshots, HTML, as well as runtime state) and produce a representation of the current scene that is adapted to best suit the agent’s current goal. A table-reader agent can operate on a scene representation that emphasizes rows, columns, and headers, and deprioritizes unrelated design details. Conversely, a form-filling agent can operate on a representation that emphasizes input elements, submit buttons, and input validation states.
Retrieval augmented imitation learning (RAIL)
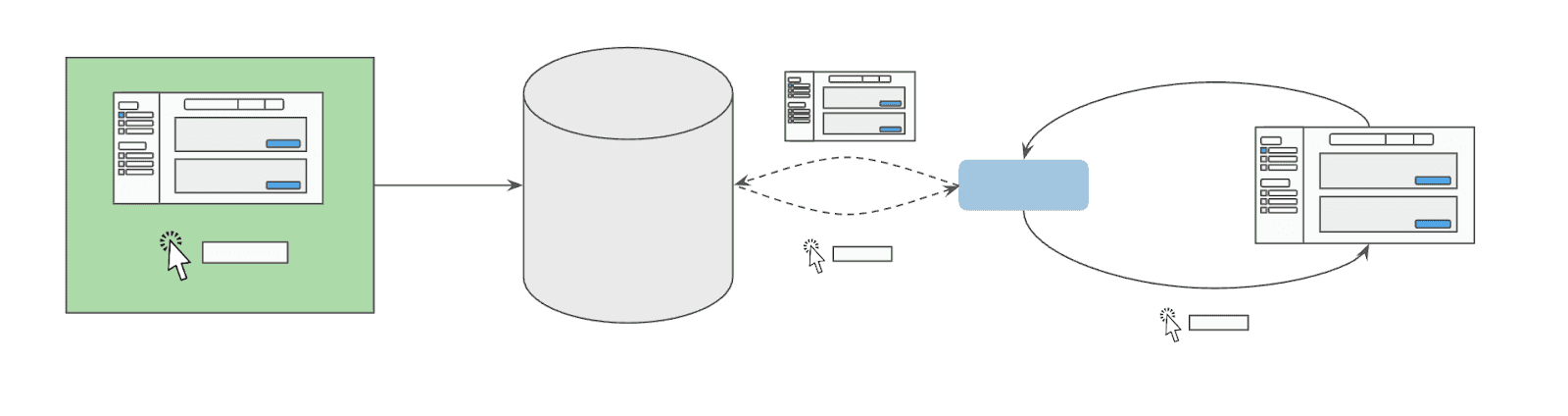
One of the most effective ways humans acquire specialized skills and knowledge is by observing experts and imitating their actions. For instance, someone who wants to learn how to hit a golf ball will likely make faster progress by watching and imitating an expert’s swing rather than researching golf swing mechanics. Demonstrations provide a more direct bridge between general knowledge and practical execution, helping novices grasp nuanced tasks more efficiently.
This principle extends beyond physical tasks: by watching how experts navigate and interact with a particular website, a learner can pick up on nuanced, real-world strategies that might remain hidden if they only relied on generalized web navigation principles. Especially for complex and ambiguously designed websites, demonstrations of experts using the website are an invaluable resource for web agents to draw from, with respect to reliable and efficient execution. However, successful imitation learning requires relevant examples to learn from. To address this, we introduce a new technique: retrieval augmented imitation learning (RAIL).
As the number of expert demonstrations increases, the naive approach of including all possible demonstrations in an agent’s context quickly starts to falter. Instead, RAIL works by embedding and storing examples of the web environment for different tasks, alongside corresponding expert-demonstrated actions. At runtime, an agent will generate an embedding of its current web environment and run a vector search to find relevant demonstrated actions. If they exist, the agent uses the relevant actions to inform its next decision.
Putting it all together
By weaving together dynamic hierarchy, adaptive scene representation, and retrieval augmented imitation learning (RAIL), our system closely mirrors the way effective human teams tackle complex challenges. Each agent delegates tasks to specialized sub-agents as needed, ensuring the most capable agent addresses each subtask. Meanwhile, agents operate with a context precisely tuned to their current objectives, filtering the vast stream of information to focus only on the signals that truly matter. Finally, by retrieving and imitating proven expert demonstrations, agents rapidly acquire new skills or refine existing ones, much as individuals learn through observation and practice.
Benchmarking
We evaluate our human-inspired multi-agent system on the Mind2Web benchmark, achieving state-of-the-art performance and surpassing leading systems such as OpenAI’s Operator and Anthropic’s Computer Use. We selected Mind2Web because it tests not only successful task completion but also per-action correctness. In contrast, other popular benchmarks like WebVoyager and WebArena focus only on goal completion, and are unopinionated about how the tasks are done. We test our automation against the heightened standard of per-step accuracy to align with real-world requirements where executing jobs in a consistent, predictable way is often important for efficiency and safety.
Methodology
To compare our system against OpenAI’s Operator and Anthropic’s Computer Use, we randomly select 100 test cases from the Mind2Web dataset. This smaller sample is required because Operator and Computer Use must be manually executed and evaluated: Operator cannot be driven by API, and Computer Use uses pixel coordinates for action output, which can’t be automatically translated to the benchmark’s action space. Instead, a human evaluator provides a task description to Operator and Computer Use from the benchmark suite, then inspects the individual actions taken by each system and compares the executed actions against the expected actions. If the agent diverges from the expected path, the human verifier restarts the flow and manually operates the website to recreate the expected prior state before continuing the evaluation.
Evaluating our system requires augmenting the test input in order to exercise the imitation learning capabilities (RAIL): we construct an embedding space of imitation examples based on the multi-modal input (HTML, screenshots, and runtime state) and ground truth actions from Mind2Web. To produce a fair comparison, we make the imitation examples available to both Operator and Computer Use in the form of additional instructions. For example, if the task is to “Buy a pop rock album CD from the United Kingdom that was released in 2016, is between £15 and £20 and in perfect condition using Discogs.com”, we generate these additional instructions:
Click Marketplace
Select Pop Rock
Select United Kingdom
Select CD
Click Show More to show more years
Select 2016
Select £15 - £20
Select Mint
Click Add to Cart
Click Place Order
We provide these instructions to Operator and Computer Use as additional context in the initial goal. We run the benchmark against Operator and Computer Use both with and without the instructions, to understand how additional instructions impact their performance.
Results
OpenAI’s Operator
Operator performed well on the sample set, with a baseline (without additional instructions) accuracy of 68%. We observed that the failure cases were often caused by misclicks—the generated instruction was correct, but the clicked element was incorrect. Given that the action output for Operator is based on pixel coordinates, there is an inherent grounding challenge that appears to remain an obstacle. Another challenge that Operator must overcome is the limitation of a vision-only environment representation. For example, the system can only detect elements that are within the viewport, which means a scrolling operation must be used to find further elements. In many cases we observed inaccurate scrolling behavior (scrolling past the target element, or not scrolling far enough).
Providing the additional instructions only boosted Operator’s performance by 3% to 71% success rate. While the additional instructions improved many cases, they also resulted in new failures in others, leading to only a modest improvement.
Anthropic’s Computer Use
Computer Use passed only 34% of test cases in the sample set. Additional instructions boosted its performance to 45%, but it still significantly underperformed Operator as well as our human-inspired multi-agent system. Computer Use shares the same high-level grounding and vision-based challenge as Operator, leveraging a screenshot-only environment and coordinates-based action space.
Invisible’s human-inspired multi-agent system
Our system achieved a 93% pass rate on the sample set and 88% pass rate on the full Mind2Web test suite (we ran the second test to check the representativeness of the sample set). Our human-inspired techniques allowed us to succeed even on tasks involving lengthy page content, high visual noise, and longer action sequences.
The recording below shows our system and OpenAI’s Operator performing a representative task from the Mind2Web benchmark suite. Our per-task latency is noticeably slower than Operator’s because of the additional overhead of the techniques we use behind the scenes—an area we’re actively working to improve.
What’s Next?
Our work hits an exciting milestone: by achieving the “first nine” of reliability, web automation agents that operate autonomously without human supervision are now within reach. This breakthrough opens the door to new, high-value applications in domains like e-commerce and finance—use cases that demand accurate and reliable execution at scale.
More importantly, our results suggest that agent cardinality—the number of specialized agents working in concert—could be a new significant scaling dimension in AI, alongside pre-training and inference-time compute. If so, simply adding more agents alone won’t suffice, agent orchestration systems will be essential to ensuring the effective management of large numbers of “micro-agents”.
Looking forward, further research into multi-agent orchestration could help us understand the true upper bound of these systems—and possibly match or exceed the capabilities of well-coordinated human teams. Achieving this will require building sophisticated frameworks that incorporate observability, fault tolerance, dynamic scaling, and other hallmarks of modern large-scale computing. The emergence of agent cardinality and orchestration as core challenges in AI indicates that we’re only at the beginning of discovering the full potential of multi-agent systems.
Future Work and Collaboration
We plan to continue advancing our core agentic platform by expanding our arsenal of human-inspired techniques and launching new applications that harness the power and flexibility of multi-agent systems. If you are interested in learning more or collaborating with us on research, development, or deployment efforts, please reach out at research@getinvisible.com. We welcome the opportunity to partner with others who share our vision for pushing the boundaries of AI agents and look forward to exploring new directions and applications together.